
22 November 2020
It's barely possible today to find someone who has never heard of ChatGPT. The model's triumph is so strong that many are expecting lots of professions to disappear. But what made ChatGPT so viral? There are several reasons.
This neural network can into context, while earlier models would lose the track after several queries. A user is always free to ask the bot to provide more details, summarize a text, or explain something they don't understand. In short, ChatGPT can do everything that an ordinary person can. And even more.

Actually, ChatGPT has a predecessor called InstructGPT. It was introduced a bit earlier but hadn't seen even part of the new model's success.
And it's all about how the neural network is trained. While ChatGPT tries to reduce the number of misleading answers and uses additional information when composing its final reply, InstructGPT's manner was too straightforward.
But this text is not about InstructGPT. Let's get to the matter.
Technology
When we discuss such sophisticated things, it makes sense to see what's going on under the hood. But, alas, OpenAI so far only provides limited access to the API.
This is why we'll try another tack and talk about the architectural elements that are available in many sources.
In fact, ChatGPT is driven by a number of noteworthy technologies, but here's a couple that deserves most attention:
- Reinforcement Learning from Human Feedback (RLHF).
- Transformer.
If you want more details, check out the article GPT for beginners: from tokenization to fine-tuning.
Without diving too deep into the maze of machine learning, we can say that RLHF is just a learning process based on human feedback. But this is far from a profound description, and it barely explains how it works.
Let's look at a simple example.
Imagine we have a model that has already learned the basic concepts from the language but the replies it returns look very clumsy. Correct as the sentences may be, they are not used in everyday language.
Bot: I want to say hello to you.
This is why a person tells the bot that nobody speaks this way, and gives a more appropriate linguistic pattern. The network receives this feedback and makes adjustments to its internal model.
Bot: I want to say hello to you.
Human: Meh, nobody says hello like that. Go with just "hello" or "hi."
Bot: Hello to you!
Human: It's better.
These adjustment iterations continue until the network achieves a certain quality level in its replies.
Everything is way more complicated there, but this example can give us the general picture. Here's what it looks like architecturally:
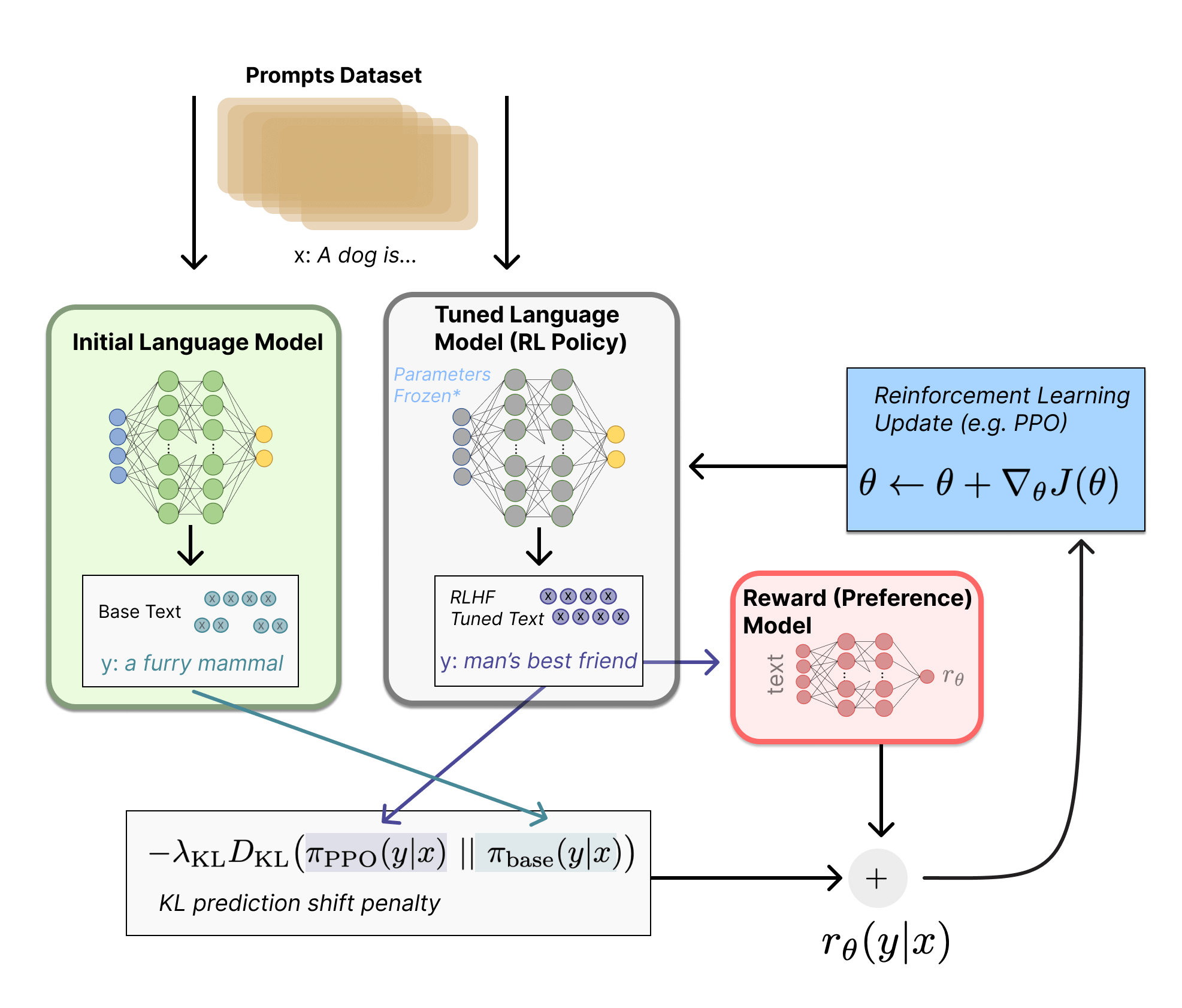
Put in crude terms, this is the essence of the RLHF method. If you want to immerse in a detailed description of all stages, check out these texts: Illustrating Reinforcement Learning from Human Feedback (RLHF) and Learning from Human Preferences.
And we are moving on to the transformer.
For starters, let's dig a little into the history of architecture. Public sources say it was introduced by the Google Brain team in 2017 as a replacement for the Recurrent Neural Network (RNN).
It's worth explaining that up to that point, RNNs based on long short-term memory (LSTM) were used to process text. And they had one significant bottleneck: they had to process the text sequentially, and that dramatically slowed down the learning rate. There were also many other pitfalls due to which developers created lots of versions of such networks.
A whole-new architecture eliminates the main drawback of its predecessors.
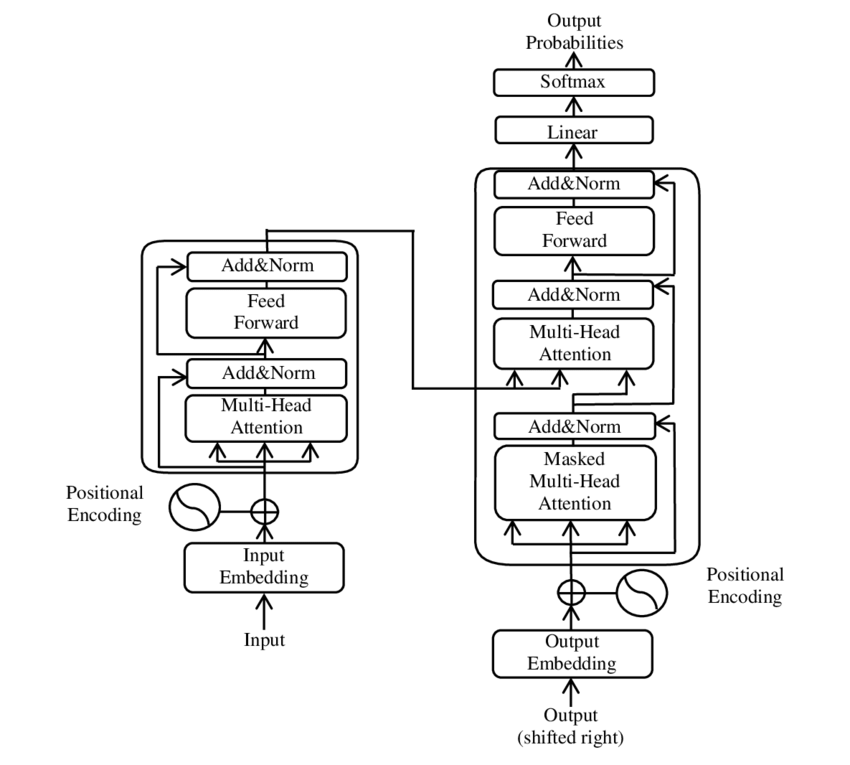
At this point, we should talk about the transformer's attention mechanism and delve into the ins and outs, but it will go far beyond the a-few-words text. You can always refer to the theoretical basis. Start with the Wikipedia text Transformer (machine learning model).
Problems
Now that we are done with architectural things, we can discuss what problems ChatGPT has—as any other new technology does.
One of them is ethical limitations. Someone may say these limitations are a must. But it's controversial.
In fact, ChatGPT might provide an incorrect answer that will only look like a correct one. This is a severe problem that it's not that easy to tackle. But if we draw a parallel with the human world, people are not always right either.
Remember that the model is very sensitive to the input text. And while it may not know the answer to one question, it can easily pop a reply after we slightly edit it.
Human: What is NLP?
Bot: Hmm. I think I don't know. What do you mean?
Human: What is Natural Language Processing?
Bot: Ah, this. Make yourself comfortable and get ready for my lecture for you.
Though OpenAI tried to protect its solution from "inappropriate" language in questions and answers, misleading replies may occur. The only way to mitigate this problem is continue learning and receiving feedback from the users.
Another problem with ChatGPT is human supervision of its learning. We call it a problem just because people can have biased opinions, and therefore the model might be biased as well. Although things may get better with more feedback, we still remember the story of Tay.
Does ChatGPT have any rivals?
There are other solutions besides ChatGPT, but they can't measure up to it in terms of popularity and hype.
Only few companies have solutions that could compete with ChatGPT so far, but we can mention a couple of them that see some media coverage:
The problem with these networks is that they are barely accessible.
LaMDA recently announced a pre-sign-up for tests, but I don't think too many people will get a chance to give it a try.
Little is known about the YaLM 2.0 version. What we are only aware of is that Yandex will build it into the search engine and that development goes at full speed. But on the other hand, they have published the pilot version of the network Knowing this, we may expect the second version to be somehow available in the distant future.
As for other networks, there is nothing but promises. For example, LAION plans to create an available chat bot similar to ChatGPT, which could be run on any PC—just like Stable Diffusion.
Some time ago, Meta published its OPT, which suggests that we may expect a bot from this social media giant. But they are overwhelmed with other problems today.

Let's see what happens.
What awaits us anyway?
Things got very tense after the release of ChatGPT. Nobody wants to lose their job to a bot.
But rather than shivering and wondering how soon a soulless machine will replace you, you might want to think how you could adapt to the new reality.

When MidJourney, Stable Diffusion, DALL-E , and many other solutions emerged, people didn't feel an urge to replace all artists with neural networks.
Some of the art professionals fell into panic, some of them are still thrilled. There was even a lawsuite against the neural networks.
But the most clairvoyant are already utilizing neural networks instead of submitting to negative thoughts.
Many already use Stable Diffusion to generate references, while the Blender community took a step further and introduced an add-on for AI-Render and dream textures.
It's worth recalling that time is cyclical. And artists were more than uptight when photography emerged. And though the need for paintings has decreased, artists haven't disappeared.
Let's sum up.

If you want to read more about this topic, refer to Vastrik's text ChatGPT. When will neural networks steal our life?, and a text on Hacker Magazine: Artists vs. AI. Figuring out the legal status of neural networks' deliverables.
Afterword
In my opinion, people should delight in seeing so much progress in the field of machine learning. Remember that these technologies are called to make our life easier.
Some don't realize it, but technological advancements are a thing that is not so easy to stop.
Just enjoy the great new solutions and don't sweat the small stuff.



